

Querying
Once the graph is built, we can start querying it. The implementation of the search functionalities can be found in the structure_search directory of the GraphRAG project.
Local Search
If you have a specific question, use the Local Search function provided by GraphRAG (additional example usage in notebook).
graphrag query \
--root ./ragtest \
--method local \
--query "What kind of retribution is Laura seeking, and why?"

Key steps in Local Search
1. Community reports, text units, entities, relationships and covariates (if any) are loaded from the parquet files in ragtest/output/, where they have been saved automatically following graph creation.
Then, the user query is embedded and its semantic similarity to the embedding of each entity description is calculated.

Snapshot of entities and their cosine distance to the user query
The N most semantically similar entities are retrieved. The value of N is defined by the hyperparameter top_k_mapped_entities in the config.
Oddly, GraphRAG oversamples by a factor of 2, effectively retrieving 2 * top_k_mapped_entities entities. This is done to ensure that sufficient entities are extracted, because sometimes the retrieved entity has an invalid ID.


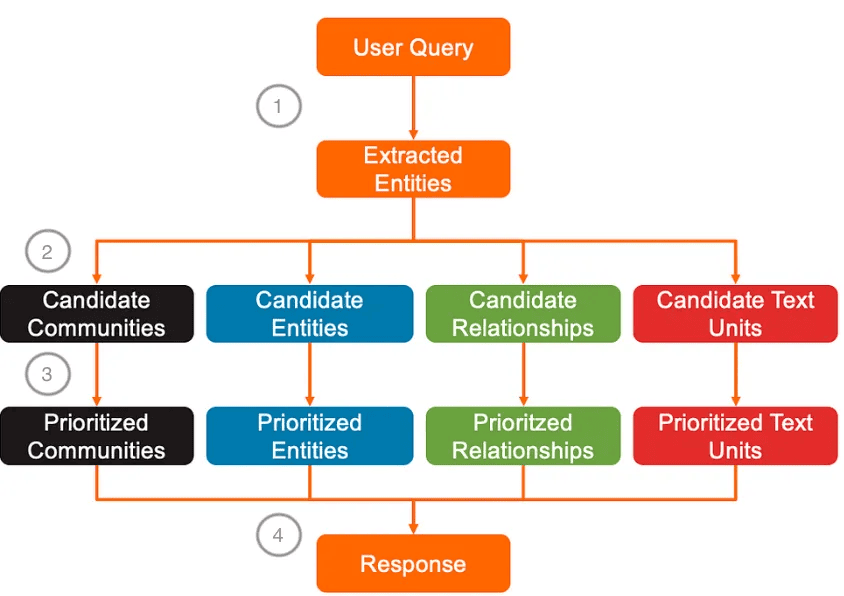
2. All extracted entities become candidate entities. The communities, relationships, and text units of extracted entities become candidate communities, candidate relationships, and candidate text units.
Specifically:
- Candidate communities are all communities that include at least one extracted entity.
- Candidate relationships are all graph edges where an extracted entities is either a source or a target node.
- Candidate text units are the chunks from the book that contain at least one extracted entity.

Summary diagram: Selection of candidate communities, entities, relationships and text units in Local Search
3. The candidates are sorted, with the most relevant items placed at the top of their respective lists. This ensures that the most important information is prioritized for answering the query.
Prioritization is necessary, because LLM context length is not infinite. There is a limit to how much information can be passed to the model. Hyperparameters set in the config determine how many context window tokens are allocated to entities, relationships, text units, and communities. By default, text_unit_prop=0.5 and community_prop=0.1, meaning that 50% of the max_tokens specified in the config will be occupied by text units, 10% by community reports, leaving 40% for descriptions from entities and relationships. max_tokens defaults to 12 000.
- Communities are sorted by their number of matches, that is the number of distinct text units in which extracted entities of the community appear. In case of a tie, they are sorted by their rank (LLM-assigned importance). Given max_tokens=12000 and community_prop=0.1, then community reports can occupy up to 1200 tokens. Only entire community reports are allowed, meaning there is no truncation — either a community report is included in its entirety or not at all.

- Candidate entities are not sorted, keeping the entities in the order of their semantic similarity to the user query. As many candidate entities as possible are added to the context. If 40% of max_tokens are allocated to entities and relationships that means up to 4800 tokens are available.

Snapshot of candidate entities
- Candidate relationships are prioritized differently depending on whether they are in-network or out-network relationships. In-network being relationships between two extracted entities. Out-network being relationships between an extracted entity and another one that is not part of the extracted entity set. Candidate relationships that are in-network are sorted by their combined_degree (sum of source and target node degrees). Candidate relationships that are out-network are sorted first by the number of links that the out-entity has to in-entities, then by combined_degree in case of a tie.


Finding in- and out-network relationships is an iterative process that stops as soon as the available token space is filled (in our example, available_tokens = 4800 — entity_descriptions). In-network relationships are added to the context first, as they are considered more important. Then, space allowing, the out-network relationships are added.

Snapshot of prioritized candidate relationships. Observe that the two first rows are the in-network relationships. Weight is not used by default and links are outdated/ incorrect for in-network relationships.
- Candidate text units are sorted by extracted entity order, followed by the number of extracted entity relationships associated with the text unit. Entity order ensures that the text units mentioning entities that are the most semantically similar to the user query get prioritized. For example, if Crímenes is the most semantically similar entity to the user query and text unit CB6F… is a chunk where Crímenes was extracted from, then CB6F… will be at the top of the list, even if there are few extracted entity relationships associated with it.

Snapshot of table showing prioritized text units
 has a property which informs from which text units it was extracted")
Every graph edge (relationship) has a property which informs from which text units it was extracted. This property makes it possible to trace the relationship of an extracted entity to the text units where it was detected.
Given max_tokens=12000 and text_unit_prop=0.5, then community reports can occupy up to 6000 tokens. As in the case of community reports, text units are appended to the context until the token limit is reached, without truncation.

Summary diagram: Sorting of candidate communities, entities, relationships and text units in Local Search
4. Finally, the descriptions of the prioritized community reports, entities, relationships, and text units — in this order — are concatenated and provided as context to the LLM, which generates a detailed response to the user query.

Summary diagram: Response generation to the user query in Local Search
Global Search
If you have a general question, use the Global Search function (additional example usage in notebook).
graphrag query \
--root ./ragtest \
--method global \
--query "What themes are explored in the book?"

1. Community reports and entities are loaded from the parquet files where they have been saved.
For each community, an occurence_weight is calculated. occurence_weight represents the normalized count of distinct text units where entities associated with the community appear. The value reflects how prevalent the community is throughout the document(s).


Snapshot of community table
2. All communities are shuffled, then batched. Shuffling reduces bias by ensuring that not all the most relevant communities are collected in the same batch.
Each batch has its communities sorted by their community_weight. Essentially, communities whose entities appear in multiple text chunks are prioritized.

Summary diagram: Batching of communities in Global Search
3. For each batch, the LLM generates multiple responses to the user query using the community reports as context and assigns a score to each response to reflects how helpful it is in answering the user’s question (prompt). Usually 5 responses are generated per batch.

Summary diagram: Response generation for each batch in Global Search
All responses are ranked by their scores and any response with a score of zero is discarded.

Table showing all responses to the user question sorted by their score
4. The texts of the sorted responses are concatenated into a single input, which is passed to the LLM as context to produce a final answer to the user’s question (prompt).

Summary diagram: Final response generation in Global Search
Conclusion
This article has walked you step-by-step through Graph Creation, Local Search, and Global Search as implemented by Microsoft GraphRAG using real data and code-level insights. While the official documentation has improved significantly since I started using the project in early 2024, this deep dive fills in knowledge gaps and shines a light on what’s happening under the hood. To date, it’s the most detailed and up-to-date resource on GraphRAG that I’ve encountered and I hope you’ve found it useful.
Now, I encourage you to go beyond the default configuration: Try tweaking parameters, fine-tuning the entity extraction prompt, or using a different indexing method. Experiment and harness the power of GraphRAG for your own projects!
