


After giving an introduction, sketching the overall architecture of our automation efforts and introducing Camunda 8 to you, today we want to shed some light on the Apache Camel centric EAI (Enterprise Application Integration) middleware solution we built.
How did we get here?
Our journey towards Apache Camel started when we had to connect another CRM system for order processing to a monolithic webshop system (Magento Commerce). Earlier connected CRM systems were integrated with synchronous API calls and/or file transfers and always lacked stability, especially in terms of handling retries, network outages etc. ending up in a lot of manual data fixing of failed transfers.
Our decision was to create a microservice which is mainly based on Apache Camel and AWS SQS for message queueing. This microservice acted as middleware between the Magento monolith and the CRM system that was responsible for mainly 2 things:
-
Error handling
-
Transformation of data into the CRM system's expected data format
It turned out that this combination was a perfect match for our requirements: While Apache Camel provided a proper domain-specific language to specify data integration and transformation tasks, SQS from AWS gave us a highly available “storage” for the data involved.
While this only met a relatively narrow requirement at this stage, a pattern became quite obvious: When two or even more systems act together, they shouldn’t technically depend on the presence or proper operation of the related systems.
After that first microservice had proven that the concept was working for our needs, this finally led to the decision to create a formalised way of creating, running, monitoring and maintaining such integration needs on some sort of own-created platform.
While one might say: “Hey, you are re-inventing the wheel!” as there are some well-established software products on the market, our decision was based on these criteria:
Costs - We evaluated several commercial products which would serve our needs but always ended up with relatively high licensing costs compared to the scope we had at this time. Additionally, we already had some Apache Camel experience in our team which helped us to get started quickly.
Flexibility - Most commercial products offer some sort of GUI for their integrations, mainly with the citizen developer in mind. We found lots of cases where more flexibility is needed to meet the requirements. GUIs are just not flexible enough in complex scenarios and classic programming skills and best practices, like unit and integration tests for example, are essential for the robustness of the whole service.
One reliable camel (beginning of 2017)
Let’s step back to the initial microservice that picked up orders from the webshop and transformed the order data into a CRM system-defined format.
The first shot of the microservice was a straightforward Spring Boot application as suggested by Apache Camel’s best practises. The compiled service ran in a very minimalistic system environment based on a centos VM with a Java runtime environment. Still, the service was designed with horizontal scaling in mind and implemented stateless and asynchronous patterns through the use of the AWS SQS (“The state is in the queues”). To scale out you just had to manually start multiple instances of the service on the VM. Not too fancy but it served our needs.
We need more Camels (mid of 2017)
Pretty soon after we started developing on our microservice for more than one project the need to have more than one such a service evolved. From a technical point of view, we were still connecting our customer-facing web systems to the CRM using our (now not so much) microservice. As the CRM has a plethora of functional features, it immediately felt wrong to build another monolith in front of it. The design guideline we went for (most of the time) was to have our microservice communicating with a system in the systems “dialect” (e.g. SAP and the JCO) while our microservices would communicate async via SQS messages in a normalized format.
Walking skeleton
When we started to split our codebase into multiple services we also developed a “walking skeleton” that helps us to spawn new services easily and reduce ramp-up costs. It also helped us to document the general architecture of our stack, so new colleagues joining our team to support our mission have a good entry point into our universe that over time grew to consist of ~30 microservices implementing ~200 integrations between systems (e.g. SAP, Salesforce Commerce Cloud, Microsoft 365 Services via Graph API (Sharepoint, Outlook, Excel, PowerPlatform), Kafka, IoT Devices, ServiceNow, FileMaker, Jamf, PimCore, SCCM, SFTP, Magento, E-Commerce fulfiller). Using this pattern minimises the need for boilerplate code and keeps things like AWS SDK client initialisation, log and environment configuration etc. done in a unified way, while still keeping things flexible for special needs. We used Spring Boot’s auto-configuration feature to achieve this.
Observability
Production use of the initial microservice showed that the observability just by looking into logfiles was OK for the start but far from perfect. Moreover, we needed some visual kpi dashboards to make our clients happy.
To overcome this shortcoming we decided to generate metrics by instrumenting our code with Micrometer to get a more detailed view on what the service was doing at what frequencies. Those metrics also serve as indicators for alerting.
Furthermore we added Hawtio to the mix. Hawtio is a web-based management console that comes with a plugin for Apache Camel routes - you just might think of it as a web frontend to Apache Camel. Among others, it provides functionality to start, stop or debug routes in production which helps a lot when unexpected things happen.
Some time later we introduced Camunda 8 to improve observability as well. But more on that later and in the last blog post of this series.
How to get data from outside our cosmos into our routes?
When dealing with data integration demands there is always a central question in place: how do we get the data or at least a pointer on the data to us, so we can start the processing. As we already had a bunch of camel routes that relied on AWS SQS Queues and had a fair amount of experience with the configuration of them (e.g. how much complexity regarding retries, timeouts, back-off, dlq, … they could take away from us) and knew how relatively inexpensive they were, in the beginning of 2018 we started looking on ways to enable our producers to produce the data into them.
-
1st approach: AWS SDK + IAM Credentials + Cross Account Policies
The first approach we did was with a team close to us. Like us, they also had a black belt in AWS so we decided to give it a shot and use the AWS native toolset to enable their apps to write into the queues in our account. In theory, it’s all just a bit of configuration and we are good to go. This would be great, as we would be as effective as possible while being able to focus on building more integrations. Technically it worked, but the hurdle even we all faced using the verbose IAM engine made us look for an alternative. -
2nd approach: REST API + OAuth Client Credentials Flow
As we initially planned to scale our EAI solution as a lean enterprise into the whole organisation and had the enterprise architecture board on our side, we had to look for an alternative that every developer team in the company could understand, regardless of the tech stack or hyper-scaler they were using. We decided to go for HTTP REST in combination with the OAuth client credentials flow for server communication and Swagger UI as living documentation. AWS offers a way to set this up, using serverless services, thus minimising the run costs. Using ApiGateway, Cognito, SQS, S3 and AWS Lambda enabled our team to set up new APIs for other teams which they could push data to in a matter of hours.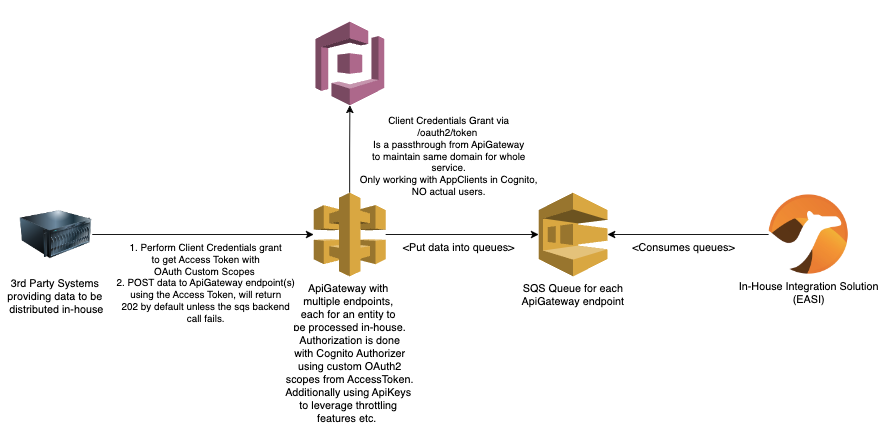
Since we launched the first APIs in 2018 in the meantime we have around 15 other teams using these APIs, sending us millions of data entries / batches per year. It works as a central entity to connect the systems in our organisation and is highly flexible. In the past years we have implemented these use cases with stacks like this:
-
Async
-
OAuth authenticated delivery of event notifications to SQS queues
-
OAuth authenticated delivery of event-driven state transfer for single entities and batches into SQS queues and/or S3 to handle “large payloads” (> 256KB)
-
OAuth authenticated HTTPS Gateway in front of Camunda 8’s grpc API
-
-
Sync
-
OAuth authenticated access to S3 Objects
-
Azure Entra ID (former AAD) authenticated proxy in front of landing pages being served by power automate
-
Calculating costs in a lambda for the employee in-house parking, storing state in DynamoDB
-
-

Let’s scale things (mid of 2019)
For about two years we had mainly built integrations for one domain of our company (e-commerce) and were at capacity with our workload. It was clear that projects would finish and mainly go into a maintenance mode. As our initial vision was to diversify, we started spreading the word and prepared to scale things. We had to move to other infrastructure for networking/security reasons anyways, so we took the chance to make the transition to a Kubernetes (k8s) environment. It was the logical next step on our DevOps journey to minimise the dependencies on other teams. With this transition, our team improved all of the following:
-
horizontal scalability of our services, we use Keda for metric based-scaling
-
stability was improved, k8s comes with the paradigm of readiness and health checks that perfectly matches SpringBoot’s extensible actuator feature
-
It is really easy to spawn new microservices, just fork a git repo with a walking skeleton including the CI (since we moved to GitLab CI) and start building things
-
We got a nice UI for our Kubernetes clusters: Rancher
What we cannot do (yet):
-
DNS stuff for ingress deployments
Scaling is great, but where is the catch?
While scaling is a good idea in terms of performance it unfortunately introduces new challenges. We particularly had to deal with the situation where certain tasks should be started exactly once on a cron schedule. Thanks to Camel we wrote our own scheduler service, that started such tasks by sending trigger messages to scheduler queues and relying on the SQS nature that only one service instance can consume the trigger message from the scheduler queue.
Over time we concluded that total statelessness isn’t achievable. We needed a shared data storage for a variety of data like semaphores, serials, avoidance of redundant API calls and others. We opted for Redis as a simple key-value store here and AWS services DynamoDB and S3 for serverless data storage.
Apache Camel and Camunda 8 (beginning of 2020)
As mentioned before and in the other posts of this series we use Apache Camel and the Camunda 8 workflow engine together. In this post, we won’t focus on the why but take a quick look at the how.
Camunda 8 offers a grpc interface to interact with its workflow engine. Camel also comes with a grpc component. This looked promising to us in the beginning. Unluckily the component’s interpretation of how grpc should be used is completely different from Camunda’s implementation of the API, rendering the combination useless out of the box. Luckily both tools offer multiple ways to use them so we came up with creating a custom camel component that in turn uses the Zeebe java client. For now this component is not public, but we hope to open-source it later on. Using this component we can now use Camunda’s Zeebe API the camel style. So a route might look like this:
from("zeebe-job://create_customer_in_crm") //process variables come alongside workflow metadata
.process(this::doWhatIsNeededToCreateTheCustomerInCrm)
.setBody().body(CompleteJobRequest.class, this::buildCompleteJobRequest)
.to("zeebe-job://create_customer_in_crm?operation=CompleteJob")With introducing the workflow engine we had to rethink some things. Beforehand most of the time we used AWS SQS to keep our state. To leverage Camunda’s potential, a lot of state could and should be kept in the engine from our experience.
What else?
If you're curious about what we currently use to run this microservice fleet, here is an unordered (and probably incomplete) list of things that we use to stay on top of things:
-
Java
-
GitLab
-
Grafana
-
Prometheus
-
Kubernetes
-
Rancher
-
checkMK
-
hawt.io
-
snyk
-
SonarCube
-
IntelliJ IDEA
-
AWS: SQS, S3, ElastiCache, Lambda, ACM, CloudWatch, DynamoDB, Cognito, CloudFormation, WAF, Route53
-
Testcontainers
-
Python
And a list of tools we used on the way to where we are now:
-
BitBucket
-
Bamboo
-
Redis (on site)
-
Graylog
-
Splunk
-
Graphite
-
NodeJS
-
Zipkin
Shout out
Being able to build such a complex framework while making our customers happy with new features is not a one-man show. We are a team of dedicated developers and architects. Props go out to the people who helped to coin the current state (alphabetical order):
-
Niels Majer
In the fifth and final part of this blog series about our automation efforts, we will give a bit of insight into how we use Power Automate.
